
- Build an ontology describing your data model
- Define Plaza triple spaces and RESTful
services - Take a look at your API
- Connecting a JavaScript client to your services
API - Building the client interface and logic
- Final result
In this tutorial the building process of a scrum board application using Plaza
is described.
The code of the application can be found at the src/plaza/examples
directory of Plaza’s git repository.
Plaza is still in a very early stage of development, so the best way to test the
application is cloning Plaza repository and built Plaza and the Scrum
application using Leiningen.
Build an ontology describing your data model
The first step in building a Plaza web application is to formalize your data model
as an ontology.
In most web development frameworks the only formal description of data is
the relational model of the tables stored in the database or the definition of
some classes in an object oriented language, that will be later transformed
somehow into tables in the database.
Building an ontology, on the other hand, means that you must collect a vocabulary with well defined semantics that
will be used to describe your application data.
Plaza supports the W3C RDF Schema
standard vocabulary to define ontologies.
Ontologies built with RDF Schema are just collections of URIs where:
- Some URIs define RDF Schema classes
- Some URIs define RDF properties
Properties define relationships between instances of different classes
or between instances of classes and some value of a certain data type. These
constrains can be stated using RDF Schema range and
domain properties.
Plaza offers some functions for easing the definition of ontologies.
The way these functions are used to describe the data layer of the scrum board
application can be found in the scrummy-clone.resources.common
name space.
(ns scrummy-clone.resources.common
(use [plaza.rdf core schemas]
[plaza.rdf.vocabularies foaf dublin-core]))
; Namespace for all shared meta data in the application
(defonce scc "http://scrummyclone.com/vocabularies/common/")
(register-rdf-ns :scc scc)
; Classes
(defonce scc:Sprint "http://scrummyclone.com/vocabularies/Sprint")
; Properties
(defonce scc:hasSprints "http://scrummyclone.com/vocabularies/hasSprints")
; Schemas
(declare-schemas-to-load
(defonce scc:Project-schema
(make-rdfs-schema foaf:Project
:title {:uri dct:title :range :string}
:hasSprints {:uri scc:hasSprints :range scc:Sprint})))
;; other definitions ...
In the previous example we introduced a new URI name space for our vocabulary
(scc). Then we added some URis in the name space that will be used to define entities in our data domain: the Sprint class
and the hasSprints property.
Finally we define a new RDF Schema class for the projects in the scrum board, of
type Friend Of A Friend
Project with a couple of associated
properties.
Building ontologies can seem easy at first, but is a really hard task. So
the first rule when building an ontology is always: don’t build an ontology,
re-use an existing one.
Nowadays every web application offering an API returns ad-hoc XML documents with their
own make up vocabulary or JSON object properties collisioning with a myriad of
other JSON objects in a flat name-space.
Working with ontologies allow us to re-use standard models for complex domains,
like Semantically-Interlinked Online
Communities (SIOC) ontology,
so we don’t need to model once again the same problem. Besides, clients
consuming our application can safely mash up our data with data
retrieved from other data sources.
Furthermore, development of ontologies can benefit from mature tools like Protege to ease the modelling task.
The following diagram, generated with Protege, shows the very simple ontology we
are building for the scrum board application.

The set of statements we have used in our ontology to describe the vocabulary of
the application domain is known in description logic and ontology modelling
parlance as the TBox or terminological box.
Conversely, statements about individuals of the classes in the TBox are a
collection of facts
known as the ABox or assertional
box.
In a Plaza application we will manipulate both components of the knowledge base.
Define Plaza triple spaces and RESTful services
Plaza library works with RDF graphs using an abstraction called triple
space. Each triple space stores a RDF graph and can be modified concurrently by
different agent using operations for writing, removing, reading and updating the
graph.
These triple spaces can be used to store semantic information about the
application domain but also as a coordination mechanism for the agents
implementing the application logic.
Besides regular agents, Plaza implements a special kind of agent that has an
associated URI and is able to translate HTTP messages into triple space
operations according to REST semantics.
In our scrum board application we need to expose the main RDFS classes in our
ontology (foaf:Project, scc:Sprint, scc:Story and scc:Task) as REST resources.
We can do that in a Clojure’s Compojure application using the
spawn-rest-resource! function and some additional steps:
- Registering the schemas we are going to use in the TBox of the application
- Creating some triple spaces to store the triples in the ABox of the application
- Registering RESTful agents with an associated URI, schema and triple space
We can found the required code in the scrummy-clone.core name-space:
;; We register the resources in the TBox
(tbox-register-schema :project scc:Project-schema)
(tbox-register-schema :sprint scc:Sprint-schema)
(tbox-register-schema :story scc:Story-schema)
(tbox-register-schema :task scc:Task-schema)
;; Triple spaces definition
(def-ts :projects (make-basic-triple-space))
(defonce *server* "http://localhost:8081")
;; Application routes
(defroutes scrummy-clone
;; Resources
(spawn-rest-resource! :project"/projects/:id" :projects)
(spawn-rest-collection-resource! :project "/projects" :projects
:id-gen-fn (fn [req env]
(let [prefix (:resource-qname-prefix env)
local (:resource-qname-local env)
id (beautify (get (:params req) "title"))]
{:id id :uri (str *server* "/projects/" id)})))
(spawn-rest-resource! :sprint "/sprints/:id" :projects)
(spawn-rest-collection-resource! :sprint "/sprints" :projects)
(spawn-rest-resource! :story "/stories/:id" :projects)
(spawn-rest-collection-resource! :story "/stories" :projects)
(spawn-rest-resource! :task "/tasks/:id" :projects)
(spawn-rest-collection-resource! :task "/tasks" :projects)
;; Static files
(route/files "/images/*" {:root "/var/www/scrummy-clone/scrummy-clone/client"})
(route/files "/css/*" {:root "/var/www/scrummy-clone/scrummy-clone/client"})
(route/files "/js/*" {:root "/var/www/scrummy-clone/scrummy-clone/client"})
; This should lead to the index
(route/files "/" {:root "/var/www/scrummy-clone/client"})
; Project canvas
(GET "/:name" request (file-response "/var/www/scrummy-clone/client/project.html")))
;; Server start
(run-jetty (var scrummy-clone) {:port 8081})
In the previous code, we first register the RDF Schema classes defined into the
TBox of the application using the function tbox-register-schema. We
use an alias for each registered class so we can refer to them easily.
Then we create a new triple space named :projects to store RDF
graphs for the individuals of the application. In this example, we are using a
basic triple space residing in memory but we could use any other available triple
space supported by Plaza.
For instance, if we decide to use Allegro Graph to
persistently store the RDF data of our application we could accomplish that
changing the triple space definition, without changing the application code.
Finally we create a new Compojure routes definition and we add REST agents
using the functions spawn-rest-resource! and
spawn-rest-collection-resource! passing as parameters the TBox
registered resource that will be exposed, a Compojure
URL template where the agent will receive HTTP messages, and the triple space
where resources will be stored.
For every exposed resource, plaza adds an ID property defined by the RDF property
http://plaza.org/vocabularies/restResourceId. This property is associated to the
:id part of in the template for single resources. By default this ID
is generated for all newly created resources using a generated UUID. In the case
of the Project resource, we want to change this default behaviour
generating URIs for each new Project resource based on the
dct:title property of the resource. This can be achieved using the
:id-gen-fn key in the definition map of the resource. This is just
one of the ways Plaza allows developers to customize the definition of REST resources.
Finally we start the application at port 8081 using Jetty invoking the
Compojure/Ring run-jetty function.
Take a look at your API
The main goal of Plaza as a web development library is to allow
developers to build beautiful RESTful APIs that can be easily consumed and
remixed by client applications, whether they are javascript clients being
executed in the browser, smartphone applications or other web application
back-ends.
Once you have the code in the previous section running you should be able to
access the defined resources using familiar conventions for RESTful applications:
- use the
AcceptHTTP header or a.formatextension
for the resource URI to select the representation of the resource - Use a
_methodparameter to issuePUTand
DELETEoperations if they are not supported by your HTTP agent. _offsetand_limitparameters can be send to
paginate a collection resource.- A
_callbackparameter with the name of a javascript function can be passed in the request to trigger a
JSONP invocation of the resource.
You can ignore the semantic features of plaza and just consume the
resources using JSON as the selected representation.
The alias used in the definition of the resource schema are used to identify the parameters in HTTP
requests and they will also be returned as the properties in the response JSON objects:
nb-agarrote ~$ curl -X POST "http://localhost:8081/projects.json?title=testproject"
{"uri":"http:\/\/localhost:8081\/projects\/testproject","id":"testproject","type":"http:\/\/xmlns.com\/foaf\/0.1\/Project","title":"testproject"}
nb-agarrote ~$ curl -X GET "http://localhost:8081/projects/testproject.json"
{"uri":"http:\/\/localhost:8081\/projects\/testproject","title":"testproject","type":"http:\/\/xmlns.com\/foaf\/0.1\/Project","id":"testproject"}
nb-agarrote ~$ curl -X DELETE "http://localhost:8081/projects/testproject.json"
{"uri":"http:\/\/localhost:8081\/projects\/testproject","title":"testproject","type":"http:\/\/xmlns.com\/foaf\/0.1\/Project","id":"testproject"}
nb-agarrote ~$ curl -X GET "http://localhost:8081/projects.json"
[]
In the previous example we can see how returned JSON objects include a
couple of additional properties: the RDFS class URI of the object and the
whole URI of the resource.
Plaza uses semantic standards to offer additional possibilities in the
consumption of generated APIs.
We could retrieve the RDF graph associated to the resource with different
encodings: N3, turtle or the standard RDF/XML serialization
nb-agarrote ~$ curl -X POST "http://localhost:8081/projects?title=testproject"
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:j.0="http://xmlns.com/foaf/0.1/"
xmlns:j.1="http://purl.org/dc/terms/"
xmlns:j.2="http://plaza.org/vocabularies/" >
<rdf:Description rdf:about="http://localhost:8081/projects/testproject">
<j.2:restResourceId rdf:datatype="http://www.w3.org/2001/XMLSchema#string">testproject</j.2:restResourceId>
<rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Project"/>
<j.1:title rdf:datatype="http://www.w3.org/2001/XMLSchema#string">testproject</j.1:title>
</rdf:Description>
</rdf:RDF>
nb-agarrote ~$ curl -X GET "http://localhost:8081/projects.n3"
<http://localhost:8081/projects/testproject>
a <http://xmlns.com/foaf/0.1/Project> ;
<http://plaza.org/vocabularies/restResourceId>
"testproject"^^<http://www.w3.org/2001/XMLSchema#string> ;
<http://purl.org/dc/terms/title>
"testproject"^^<http://www.w3.org/2001/XMLSchema#string> .
Plaza also offers an alternative JSON representation for the resources where
instead of a single JSON object, an array of arrays containing the set of
triples for the resource is returned. This serialization can be retrieved using
the js3 format.
nb-agarrote ~$ curl -X GET "http://localhost:8081/projects.js3"
[["http:\/\/localhost:8081\/projects\/testproject",
"http:\/\/www.w3.org\/1999\/02\/22-rdf-syntax-ns#type",
"http:\/\/xmlns.com\/foaf\/0.1\/Project"],
["http:\/\/localhost:8081\/projects\/testproject",
"http:\/\/purl.org\/dc\/terms\/title",
{"value":"testproject",
"datatype":"http:\/\/www.w3.org\/2001\/XMLSchema#string"}],
["http:\/\/localhost:8081\/projects\/testproject",
"http:\/\/plaza.org\/vocabularies\/restResourceId",
{"value":"testproject",
"datatype":"http:\/\/www.w3.org\/2001\/XMLSchema#string"}]]
These resources are retrieved from triples stored in the ABox of the
application. Plaza also offers the possibility to retrieve the schema
information for each resource stored in the TBox. This meta information is
exposed as an additional resource (a meta-resource?) accessible in the URI of
the resource with an additional _schema suffix:
nb-agarrote ~$ curl -X GET "http://localhost:8081/projects/_schema.n3"
<http://purl.org/dc/terms/title>
<http://www.w3.org/2000/01/rdf-schema#domain>
<http://xmlns.com/foaf/0.1/Project> ;
<http://www.w3.org/2000/01/rdf-schema#range>
<http://www.w3.org/2001/XMLSchema#string> .
<http://plaza.org/vocabularies/restResourceId>
<http://www.w3.org/2000/01/rdf-schema#domain>
<http://xmlns.com/foaf/0.1/Project> ;
<http://www.w3.org/2000/01/rdf-schema#range>
<http://www.w3.org/2001/XMLSchema#string> .
<http://xmlns.com/foaf/0.1/Project>
a <http://www.w3.org/2000/01/rdf-schema#Class> .
<http://scrummyclone.com/vocabularies/hasSprints>
<http://www.w3.org/2000/01/rdf-schema#domain>
<http://xmlns.com/foaf/0.1/Project> ;
<http://www.w3.org/2000/01/rdf-schema#range>
<http://scrummyclone.com/vocabularies/Sprint> .
Again, this information is also available in all the possible representations,
including JSON and JS3.
Exposing meta-information about resources opens the door to
automatically processing this resources. Plaza tries to make automation easier
supporting (a slightly modified version) of the hRESTS proposed
standard for RESTful semantic web services.
hRESTS uses the W3C submitted standard proposal WSMO ontology to describe as a RDF
graph important details of the resource:
- a list of operations that can be issued to the resource
- the URI template where the resource is accessible
- a set of input messages that can be passed in the request
- a set of output messages returned by the service
Since we are using the RDF data model in our resources some difficult tasks like
service grounding are easily accomplished.
hRESTS service descriptions for resources can be retrieved using the
single_resource_service and
collection_resource_service suffixes for resource URIs.
One interesting possibility of hRESTS is offering a RDFa encoded version of the
service description. HTML+RDFa versions of service descriptions generated by
Plaza can be used at the same time as documentation for developers consuming the
API as well as a description that can be automatically processed by software
applications, once they have extracted the RDF graph embedded in the HTML document:

Plaza generates HTML+RDFa representations for every resource, schema and service
description, so all the resources in the API can be rendered with a web browser.
Connecting a JavaScript client to your services
Once we have generated our API, the next step is to create a client that can be
used to do interesting things with the semantic data exposed by these services.
As part of Plaza, we are developing a javascript library and some tools that can
ease the development of javascript clients. The first step is to create a new
HTML document including jquery, jqueryUI and Plaza’s plaza.js and plaza-ui.js
libraries:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" />
<title>Scrummy</title>
<link type="text/css" href="css/jquery-ui.css" rel="stylesheet" />
<link type="text/css" href="css/plaza-ui.css" rel="stylesheet" />
<script type="text/javascript" src="js/jquery.js"></script>
<script type="text/javascript" src="js/jquery-ui.js"></script>
<script type="text/javascript" src="js/plaza.js"></script>
<script type="text/javascript" src="js/plaza-ui.js"></script>
<script type="text/javascript">
$(function(){ });
</script>
</head>
<body></body>
</html>
We can now retrieve this document from our running Jetty server and then, we can open a
tool like Firebug to introduce the following code:
PlazaUI.Widgets.Toolbox.extend().attach();
A Toolbox with some utilities to test the API should appear:

The toolbox can be used to load schemas, service descriptions and connect them
to local triple spaces.

The toolbox can also be used to create new instances of a resource, loading
resources or browsing the listing of triples stored in a triple space.
Once we have tested that the API is working correctly and we have created
triple spaces connected to the required services, we can ask the toolbox to
generate some javascript code replicating our current state so we can start
coding the logic of our javascript client:

This is only a convenience since, the generated code is pretty straight forward.
Plaza.setup(
// Schemas
Plaza.TBox.registerSchema("http://localhost:8081/projects/_schema.json"),
Plaza.TBox.registerSchema("http://localhost:8081/sprints/_schema.json"),
Plaza.TBox.registerSchema("http://localhost:8081/stories/_schema.json"),
Plaza.TBox.registerSchema("http://localhost:8081/tasks/_schema.json"),
// TripleSpaces
Plaza.ABox.TripleSpace.connect("projects", {"collectionResource": "http://localhost:8081/projects/collection_resource_service.json",
"singleResource": "http://localhost:8081/projects/single_resource_service.json"}),
Plaza.ABox.TripleSpace.connect("sprints", {"collectionResource": "http://localhost:8081/sprints/collection_resource_service.json",
"singleResource": "http://localhost:8081/sprints/single_resource_service.json"}),
Plaza.ABox.TripleSpace.connect("stories", {"collectionResource": "http://localhost:8081/stories/collection_resource_service.json",
"singleResource": "http://localhost:8081/stories/single_resource_service.json"}),
Plaza.ABox.TripleSpace.connect("tasks", {"collectionResource": "http://localhost:8081/tasks/collection_resource_service.json",
"singleResource": "http://localhost:8081/tasks/single_resource_service.json"}),
function(){
// application code here
});
The function Plaza.TBox.registerSchema retrieves the RDF
description of a remote resource and inserts it into the TBox of the javascript
application. The function Plaza.ABox.TripleSpace.connect creates a
new triple space connected to a remote resource using the provided alias. The
hRESTS resource describing the service resource must be provided as an argument. To avoid
problems parsing RDF formats, only the JSON representation is supported at the
moment.
Once this task is accomplished, we have a javascript client connected to the
back-end resources and we can start building our application using the semantic
meta-data exposed by our scrum API.
Building the client interface and logic
Our scrum board application will be built using two main HTML documents:
index.html where new scrum boards will be created and
project.html that will render the scrum board properly.
To create a new resource, we can use the Plaza.ABox.createEntity
function passing as a reference the triple space where the entity will be stored
and a JSON object with the values for the new resource as described by the API.
Resources in the triples space can be retrieved using the function
Plaza.ABox.findEntityByURI function and providing the URI of the
resource to load.
In the index.html document the title of the project introduced
in the new project form is used to create a new Project resource and, once the
resource is created, the browser is redirected to the project.html
document, using the value of the
http://plaza.org/vocabularies/restResourceId property for the resource
to complete the URI:
Plaza.ABox.createEntity("projects",{"title": title}, function(evt){
if(evt.kind == "error") {
PlazaUI.Utils.showDialog("Error", "The project could not be created:"+evt.error);
} else {
// The URIs of the created resources
var project = Plaza.ABox.findEntityByURI(evt.uris[0]);
window.location = Scrummy.domain + project.restResourceId;
}
});

In the project.html document, we need to load the project
resource as well as all the sprints and tasks depending on this project.
We can use the functions Plaza.ABox.loadInstance and
Plaza.ABox.loadInstances to load resources from a remote
service and insert the triples in a local triple space.
When Story and Task resources are retrieved and
inserted into local name spaces, the user interface must be updated to show the
new information. Instead of providing callbacks for each function, Plaza javascript
library allows you to register observers for a whole triple space or a single
entity in a triple space that will be invoked when a new entity is inserted,
removed or updated in that triple space. These observers are used to update
the user interface accordingly:
Plaza.ABox.startObservingSpace("stories", Plaza.ABox.EVENTS.CREATED, this,
function(_space, _event, entity) {
console.log("Created story: " + entity._uri);
// UI code here
Scrummy.insertStory(entity);
});
Plaza.ABox.startObservingSpace("tasks", Plaza.ABox.EVENTS.CREATED, this,
function(_space, _event, entity) {
console.log("Created task: " + entity._uri);
// UI code here
Scrummy.insertTask(entity);
});
When these observers receive a new notification, the new story or the new
task are inserted into the user interface according to its priority or status properties.
These mechanisms plus the capacity to associate standard semantics to the
data retrieved from the backend, makes possible writing graphical components
that can be re-used with different resources. For example, it could be possible
to build a graphical component
capable of rendering the position in a map of every object with RDF properties for
longitude, latitude or a location property.
Plaza javascript library offers a couple of base objects:
PlazaUI.EntityWidget and PlazaUI.SpaceWidget that can
be used as the foundation for such graphical components.
These widgets can also be linked with each other, so changes in the entity that
is being rendered by one
widget can be transmitted to the linked widgets and all the graphical components
can be updated at the same time.
These classes are used by the Plaza Toolbox to build forms for creating
resources or showing the list of triples in a triple space.
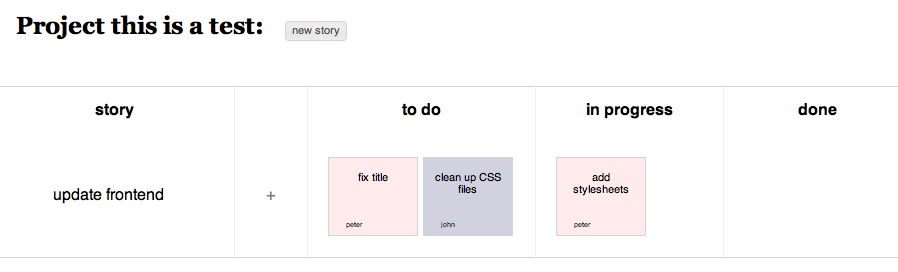
Final result
Previous sections covered all the Plaza features required to build the
scrum board application, now the only remaining details require a little bit of jQuery magic and CSS
voodoo to build the user interface of the application. A small video demo of the
final result can be found here:
A lot of functionality
present in a real scrum board application is
missing, since we were just trying to show the main ideas driving development of
Plaza. The code of the application can be downloaded from the Plaza repository in
github.